Python机器学习快速入门1#
这个系列主要要讲的是借助[Building Machine Learning Systems with Python.2Ed]这本书来入门机器学习。主要目的是在较短时间内对机器学习有个大体认识,并整理一些资源。 前提是要有一点python经验,能研究源代码(推荐用pycharm),有一点算法经验,能上google找资料。例子代码在https://github.com/luispedro/BuildingMachineLearningSystemsWithPython。代码量不大,请坚持看完并多摆弄一下。另外要多看scikit-learn官方例子和文档,http://scikit-learn.org/dev/auto_examples/
chapter01.介绍#
这章做基本的读取数据,画分布图,多项式拟合。熟悉一下常用的工具。
import scipy as sp
import matplotlib.pyplot as plt
data = sp.genfromtxt("data/web_traffic.tsv", delimiter="\t") # 读数据(可以从scipy模块直接调用numpy)
print(type(data))
print(data.shape)
x = data[:, 0] # 取0列的所有行
y = data[:, 1] # 取1列的所有行
print(x.shape)
x = x[~sp.isnan(y)] # sp.isnan(y)可取得y每个元素的isnan结果。结果就剔除了1列中内容为nan的数据。
y = y[~sp.isnan(y)]
plt.scatter(x, y, s = 20) # 画分布图
fp1, residuals, rank, sv, rcond = sp.polyfit(x, y, 3, full = True) # 最小二乘多项式拟合,可自选degree即次数。
print("Model parameters: %s" % fp1) # 多项式各项系数
print(residuals, rank, sv, rcond)
f1 = sp.poly1d(fp1) # 由系数生成多项式类型
print(f1)
print(type(f1))
def error(f, x, y): # 误差平方和
return sp.sum((f(x)-y)**2)
print(error(f1, x, y))
fx = sp.linspace(0,x[-1], 1000) # 生成x轴
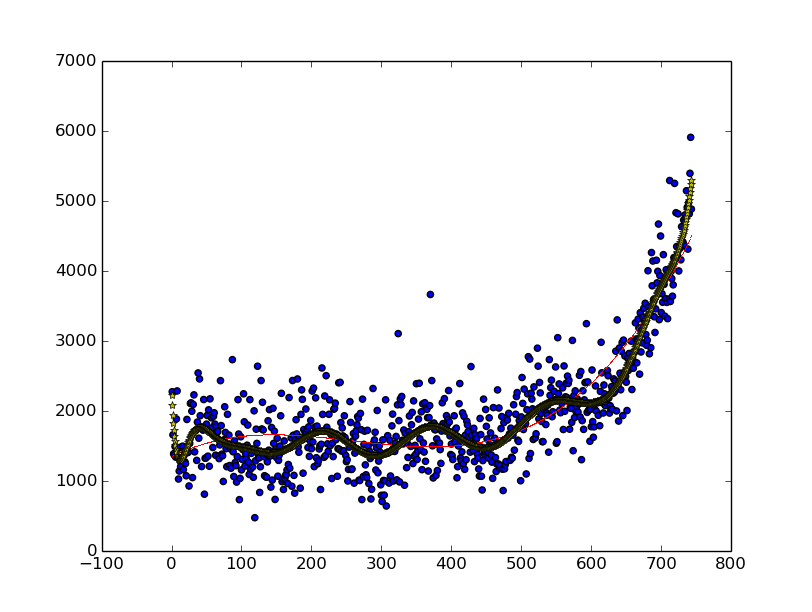
plt.plot(fx, f1(fx), 'r,', linewidth=3) # f1(fx)生成y轴,plot画线。
fp2 = sp.polyfit(x, y, 20) # 用20次来拟合
f2 = sp.poly1d(fp2)
plt.plot(fx, f2(fx), 'y*', linewidth=5, markersize = 6)
print(error(f2, x, y))
plt.show() # 显示,蓝点为分布图,红线为3次拟合,黄色五角星线为20次拟合。
可以改变拟合的次数看看效果。
chapter02.分类初步#
1.鸢尾花#
现有三种鸢尾属植物,四个属性。萼片长度,萼片宽度,花瓣长度,花瓣宽度。 要求根据统计数据建立模型,以识别新数据。 这个属于分类问题(classification)和监督式学习(supervised learning),常见的应用有区分垃圾邮件等。
我们尝试用某个属性把植物给区分开。 先从四个属性里挑6种配对并画成2d图形。
from matplotlib import pyplot as plt
# We load the data with load_iris from sklearn
from sklearn.datasets import load_iris
# load_iris returns an object with several fields
data = load_iris()
print(type(data))
print(data)
feature_names = data.feature_names # 四种属性'萼片长度' '萼片宽度' '花瓣长度' '花瓣宽度'
target_names = data.target_names # 三个种类'setosa' 'versicolor' 'virginica'
target = data.target # 每组属性所属的实际种类
features = data.data # 属性数据
print(feature_names)
print(target_names)
fig,axes = plt.subplots(2, 3) # 2x3六个子图
print(fig)
print(axes)
#print(axes.flat[0])
pairs = [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)] # 6种属性组合
# Set up 3 different pairs of (color, marker)
color_markers = [
('r', '>'),
('g', 'o'),
('b', 'x'),
]
for i, (p0, p1) in enumerate(pairs): # 6种属性组合
ax = axes.flat[i]
print(ax)
for t in range(3): # 每个图都画出3个种类
# Use a different color/marker for each class `t`
c,marker = color_markers[t]
ax.scatter(features[target == t, p0], features[
target == t, p1], marker=marker, c=c)
ax.set_xlabel(feature_names[p0])
ax.set_ylabel(feature_names[p1])
ax.set_xticks([])
ax.set_yticks([])
fig.tight_layout()
fig.savefig('figure1.png')
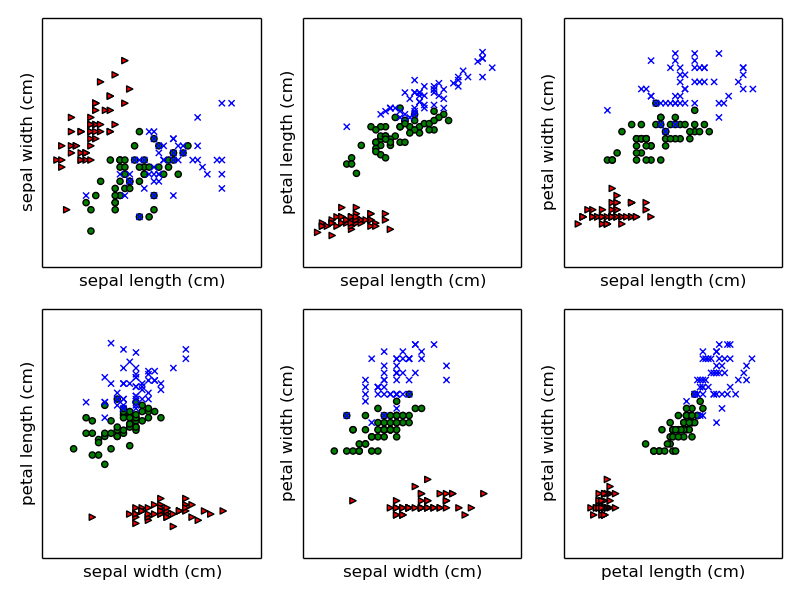
通过观察可以发现以花瓣长度和花瓣宽度这对组合可以很完美地把红色三角形也就是setosa区别开。 我们可以验证一下花瓣长度,发现确实setosa的花瓣长度最大为1.9,而其他植物的花瓣长度最小也达到了3。 所以随便找一个1.9到3之间的值就可以把setosa挑出来,而且没有误差。
如何区分剩余的两种植物? 思想就是遍历所有属性的每一条数据,以当前数据作为阈值,以这个阈值做一遍区分,然后对比真实数据看准确率,最后得出一个最好属性以及其阈值。 代码见stump.py。
2.cross-validation#
刚才我们把现有的数据既用来训练机器,又用来测试,这样好像没有说服力。 于是我们想到用一部分数据做训练,另一部分做测试,这样就浪费了数据,我们又不甘心。 而且可能产生较大误差,比如用来测试的数据刚好与训练的数据有较大偏差。 于是有了交叉验证(https://en.wikipedia.org/wiki/Cross-validation_%28statistics%29)。 最简单的一种交叉验证就是把数据分成x组,做x次训练和测试。每次用1组没有测试过的数据做测试,其他x-1组做训练。
3.knn(k-nearest neighbors)#
现在来看个新的分类算法:knn(最近邻)算法。 以2d为例,思想就是在2d平面上找k个离当前数据最近的数据,然后把当前数据与k个最近数据中的多数种类视为同类。距离算法可选直线距离、曼哈顿距离等等,需根据具体数据来选取。
那么knn的步骤为: 遍历测试输入,在训练数据中找距离当前输入最近的k个值,找到其中的多数种类,做为当前输入的预测结果。 然后统计准确率。整个数据做交叉验证,得出最终准确率。 这个算法可能会陷入局部最优,不容易得到全局最优解,联想到了模拟退火算法。google一下,确实有相关的研究。
作者给出了代码见seeds_knn.py,是暴力算法,没有优化。 要优化的话得研究近邻搜索算法: https://en.wikipedia.org/wiki/Nearest_neighbor_search https://en.wikipedia.org/wiki/K-d_tree https://en.wikipedia.org/wiki/Cover_tree https://en.wikipedia.org/wiki/Ball_tree 感谢http://my.oschina.net/u/1412321/blog/194174
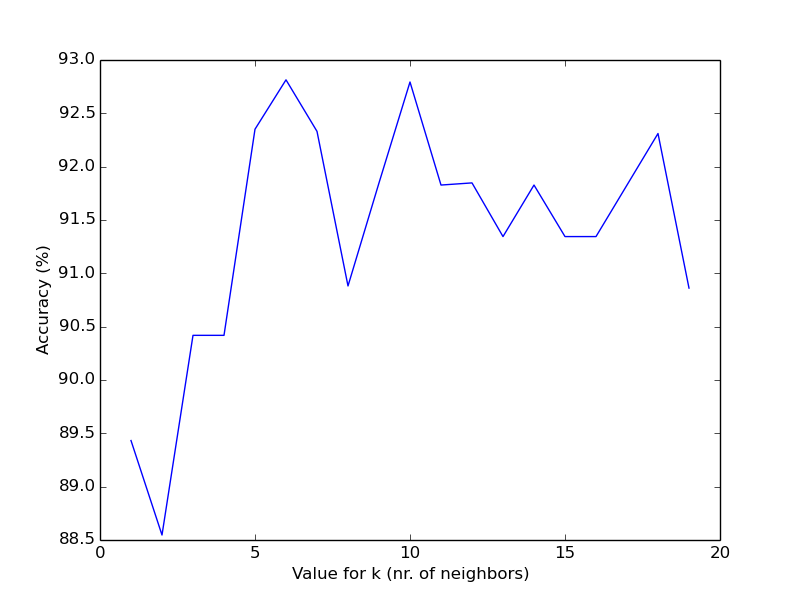
scikit-learn提供了的现成的函数,非常方便,几行代码就能把交叉验证、knn框架搭建出来。 代码见seeds_knn_increasing_k.py,里面比较了取各种k值得到的准确率。 这次的数据有7个属性,3个种类。
import numpy as np
from matplotlib import pyplot as plt
from load import load_dataset
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cross_validation import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
features, labels = load_dataset('seeds')
print(features)
print(labels)
# Values of k to consider: all in 1 .. 160
ks = np.arange(1, 20)
# We build a classifier object here with the default number of neighbors
# (It happens to be 5, but it does not matter as we will be changing it below
classifier = KNeighborsClassifier() # knn分类器
print(classifier)
classifier = Pipeline([('norm', StandardScaler()), ('knn', classifier)]) # 做流水线。先预处理数据,做标准化。再进knn算法。
print(classifier)
# accuracies will hold our results
accuracies = []
for k in ks:
print('k = %d' % k)
# set the classifier parameter
classifier.set_params(knn__n_neighbors=k) # 设置参数
crossed = cross_val_score(classifier, features, labels) # 交叉验证
print(crossed)
# Save only the average
accuracies.append(crossed.mean()) # 均值
accuracies = np.array(accuracies)
# Scale the accuracies by 100 to plot as a percentage instead of as a fraction
plt.plot(ks, accuracies*100)
plt.xlabel('Value for k (nr. of neighbors)')
plt.ylabel('Accuracy (%)')
plt.savefig('figure6.png')
scikit-learn实现了两种nn分类器,也就是分类算法,一个是KNeighborsClassifier,找最近的k个数据,一个是RadiusNeighborsClassifier ,分析一定半径内的所有数据。 KNeighborsClassifier更常用,knn中的权重计算也有讲究,可用’unioform’,表示所有临近数据的权重都一样。 或用’distance’,临近数据的权重与自己与测试点的距离成反比。 还可以提供自己的算法以满足特殊要求。 还可指定搜索算法,可指定kd-tree、ball-tree、暴力搜索还可选’auto’让库自己决定。
Pipeline类可以把多个操作组成一个pipeline,比如先对数据做标准化,再做knn。 每个操作写成一个字符串名字和类变量的tuple,非常简洁。 可以用set_params来给pipeline里的各个组件设参数,参数名字要写成”组件名字__组件本身参数”。
跟踪一下scikit-learn源码,可以看到在KNeighborsClassifier的kneighbors中, 默认使用的距离算法为余弦距离,见sklearn/metrics/pairwise.py里的cosine_distances。 只要所选的距离算法能处理多维数据,那么我们就可以直接用多维数据作为分类器的输入,只要训练数据与测试数据的维度也就是特征数量匹配就行,否则scikit-learn会报维度不匹配的错误。
例子中经常处理二维或三维数据是为了能画出来,从而对算法有个直观感受。后面会讲到降维的方法。 http://dataunion.org/11710.html总结了一些距离算法。 http://ojs.pythonpapers.org/index.php/tppsc/article/view/135。这里有35种距离的python实现(Distance Coefficients between Two Lists or Sets)。
请阅读http://scikit-learn.org/stable/modules/neighbors.html,里面有大量nb的资料和例子。
figure4_5_sklearn.py中选两个属性做knn,比较了对原始数据做不同处理和选取不同的k值得到的结果,并画四边形伪彩色图。