Python机器学习快速入门3#
chapter05.分类I#
这一章讲对帖子进行分类。帖子的特征为词数、时间、链接数、图片数等等,目标值为好或者坏,帖子的分数为正就是好,为负就是坏。 数据可以在这里下载 https://archive.org/download/stackexchange
先预处理数据,见so_xml_to_tsv.py。
Posts.xml的结构:一个帖子一个row,各种字段。Body是帖子的主内容,html编码。PostTypeId=1为问题,2为回答。
1. 把一个帖子转化成这个形式:
Id ParentId IsAccepted TimeToAnswer Score Text NumTextTokens NumCodeLines LinkCount NumImages
即id,父id,是否被采纳,距离提问的时长,分数,文本(去掉所有<>标签),token数(text中的空格数),代码行数(匹配'<pre>(.*?)</pre>'),超链接数,图片数。
存filtered.tsv
2. 每个回答记录这么一条数据:meta[ParentId].append((Id, IsAccepted, TimeToAnswer, Score))
最后整个dict存filtered-meta.json
python3下open文件时记得统一加encoding = ‘utf8’,否则写字符串时会有b前缀。
3. chose_instances.py再对当前的数据进行筛选。有几种方法,默认选的’negative_positive’。 对于filtered-meta.json的每一个问题,如果答案中有正分有负分,那么就保留问题帖子、最高分答案和最低分答案。 默认取3000个,我一共取了9000个。
4. 对于每个保留的帖子,以id,text的形式写入chosen.tsv,把score等信息存入chosen-meta.json
classify.py开始分类。代码比较繁琐,不贴出来了。
prepare_sent_features()读chosen.tsv。用nltk.sent_tokenize()和nltk.word_tokenize()对帖子做分词,统计每个主贴下帖子的平均句子数和词数等等信息,作为特征。
一共八个特征: ‘NumTextTokens’, ‘NumCodeLines’, ‘LinkCount’, ‘AvgSentLen’, ‘AvgWordLen’, ‘NumAllCaps’, ‘NumExclams’, ‘NumImages’
qa_X存了所有答案各自的八个特征值。 plot_feat_hist()画出每个特征值的直方图。 qa_Y存了每个答案的标签(这里可选好或坏,score大于0就算好) 那么到此数据就准备好了,可以进行分类了。
这里注意cross_validation.KFold已经过时,换成model_selection.KFold,用法见源码注释。
先尝试行knn算法,k选5,作者从一个特征起,加到四五个,准确率有所上升,但继续加准确率不再上升。 knn对所有特征一致对待,但各个特征的重要程度常常是不一样的。 如果想要提高准确率,怎么办呢? 可以增加数据量、改变模型参数(这里指knn的k)、改特征、干脆换模型。作者说实际生活中人们经常随机改变这些值来寻找比较好的配置。
这里谈到偏差与方差的权衡(Bias–variance tradeoff) https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff 偏差来源于对数据的错误假设(比如建的模型过于简单),通常会导致欠拟合。 方差代表训练结果中的波动。一般模型越复杂,拟合程度越大,方差越大。 这两个错误根据模型复杂度通常呈此消彼长的趋势。 参考 https://www.zhihu.com/question/27068705
作者试验了各种组合:不同的数据规模,不同的特征数,不同的k值。发现k取40时才能达到一个相对满意的结果,其他再怎么折腾好像也没什么起色。但是40nn太耗时了,而且数据越多越耗时,显然不实际。那么换个模型试试。
注: 安装nltk组件 import nltk nltk.download_gui() 选punkt
utils.py pylab.hist之前 bins转int
classify.py 170左右 len(scores_to_sort) / 2 转成int
作者要用的是逻辑回归。我们先看看基本的线性回归。
线性回归#
假定有一组训练数据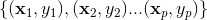 包含p项,x为粗体表示向量,即一组特征数据,包含子项
包含p项,x为粗体表示向量,即一组特征数据,包含子项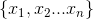 。
。
线性回归就是要把特征数据拟合到一个线性方程上。先考虑n=1即特征为1维的情况,我们可以设一个方程 描述所有数据点。为什么是约等于,因为一般不可能找到一条直线使所有数据点都在这条直线上。我们要做的是找一条直线,让所有数据尽可能好地散布在这条直线旁,从而让这条直线能够反映出训练数据的趋势。
描述所有数据点。为什么是约等于,因为一般不可能找到一条直线使所有数据点都在这条直线上。我们要做的是找一条直线,让所有数据尽可能好地散布在这条直线旁,从而让这条直线能够反映出训练数据的趋势。
以什么标准确定这条直线(即b, w这两个值)呢?最小二乘法是个常用的方法,即要让所有数据点误差的平方和最小。即要使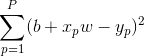 最小。这个问题的常用解法为梯度下降法和牛顿法,涉及到凸函数等知识。
最小。这个问题的常用解法为梯度下降法和牛顿法,涉及到凸函数等知识。
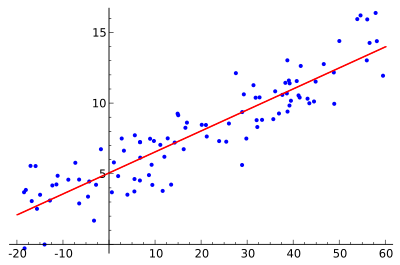
一维特征的线性回归可以在2d图形上很直观地观察。
当n>1即特征为多维时,线性方程变为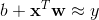 (x和w都变为多维)
n=1时数据分布在二维空间的一条直线周围。n=2时数据分布在三维空间的一个平面周围。n>2时数据分布在n+1维空间的一个所谓超平面周围。
(x和w都变为多维)
n=1时数据分布在二维空间的一条直线周围。n=2时数据分布在三维空间的一个平面周围。n>2时数据分布在n+1维空间的一个所谓超平面周围。
多维情况同样可以用最小二乘法找超平面,使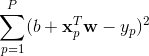 (所谓的损失函数)值最小。
(所谓的损失函数)值最小。
http://scikit-learn.org/stable/modules/linear_model.html https://en.wikipedia.org/wiki/Linear_regression
逻辑回归#
逻辑回归的核心函数是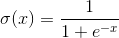 ,所谓Z型函数。
,所谓Z型函数。
https://en.wikipedia.org/wiki/Sigmoid_function
图形是这样的:
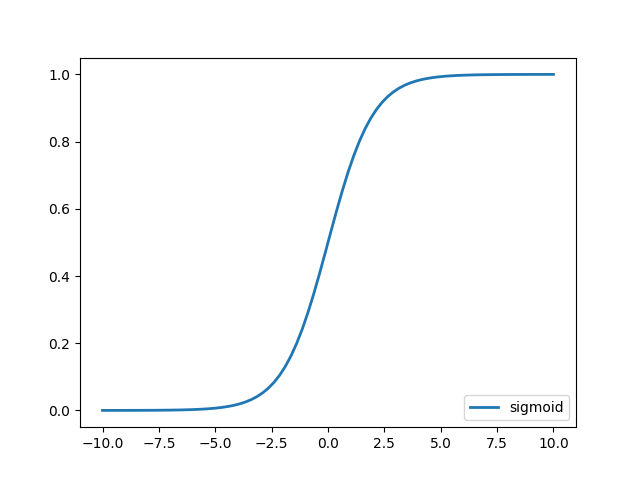
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
x = np.linspace(-10, 10, 80)
line = ax.plot(x, 1 / (1 + np.exp(-x)), linewidth = 2, label = 'sigmoid')
ax.legend(loc = 'lower right')
plt.show()
它的值在0和1之间,可看作概率,比较合适用作0/1分类。比如判断是否有病、判断性别、预测能否通过考试等等。 https://en.wikipedia.org/wiki/Logistic_regression
给x加个系数w可以改变曲线的所谓饱和速率:
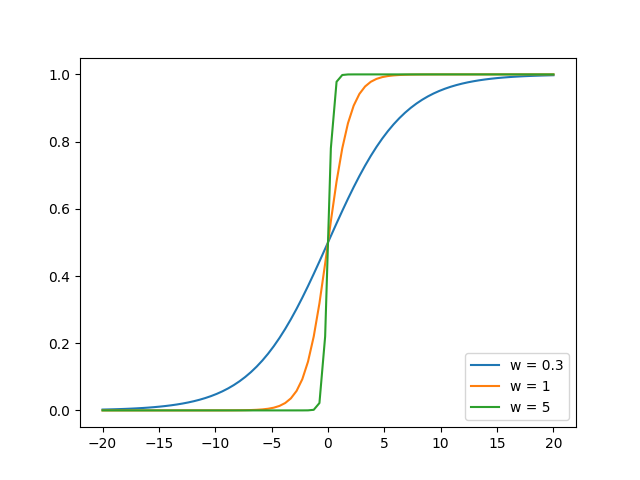
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
x = np.linspace(-20, 20, 80)
line = ax.plot(x, 1 / (1 + np.exp(-0.3 * x)),label = 'w = 0.3')
line = ax.plot(x, 1 / (1 + np.exp(-1 * x)), label = 'w = 1')
line = ax.plot(x, 1 / (1 + np.exp(-5 * x)), label = 'w = 5')
ax.legend(loc = 'lower right')
plt.show()
再加个参数b让曲线可以左右移动,Z型函数变为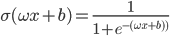 到此就可以以线性回归的方法来拟合数据了。
到此就可以以线性回归的方法来拟合数据了。
为什么要用这个Z型函数?这里有些讨论: https://www.quora.com/Logistic-Regression-Why-sigmoid-function https://stats.stackexchange.com/questions/162988/why-sigmoid-function-instead-of-anything-else 两个表面的原因是值域在0和1之间和导数容易计算。
一维特征下线性回归和逻辑回归的图形对比例子:
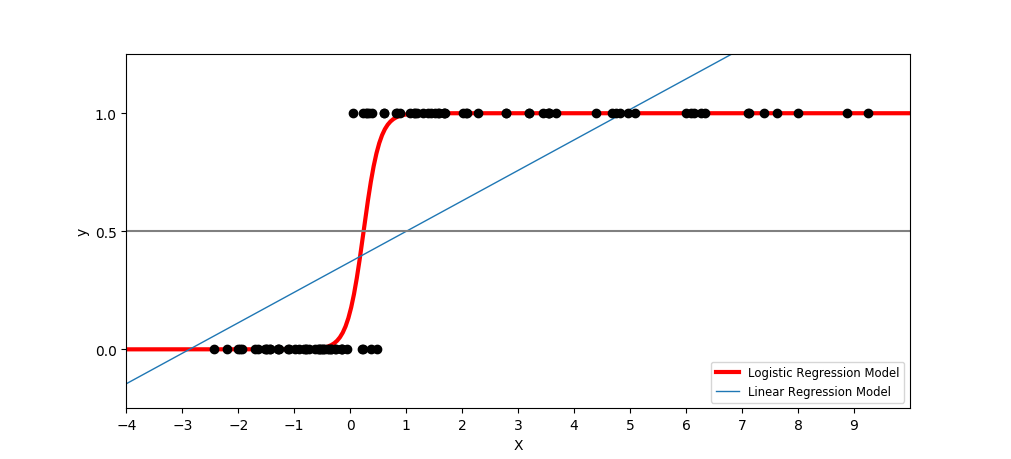
与线性回归类似,最小二乘法损失函数为: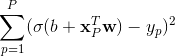
这个损失函数是”非凸”的,例如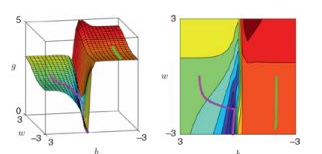
摘自[Machine Learning Refined_ Foundations, Algorithms, and Applications],这本书里有不少好的内容。
其中紫色和绿色的线是两次梯度下降法的轨迹,分别从不同起点开始。可见如果从右边开始,就会陷入局部最优。正则化(regularization)通过在损失函数后加一个’凸’项来缓解这个问题。
sklearn的LogisticRegression类的penalty参数默认为l2正则化,C参数为正则化强度(越小强度越大)。
作者用逻辑回归来分类帖子,使用不同的C值,发现表现只好了一点点。 作者越来越觉得觉得还是数据噪声太大或者特征集不合适-_-;开始反思,并且用工具来给分类工作测指标。
ROC曲线可以查看在选择不同阈值的情况下分类器的表现。
它显示一个二维曲线,横轴为FPR(false positive rate),纵轴为TPR(true positive rate)。曲线下的面积称作AUC(Area Under Curve)。术语和原理详见 https://en.wikipedia.org/wiki/Receiver_operating_characteristic。图形是这个样子:
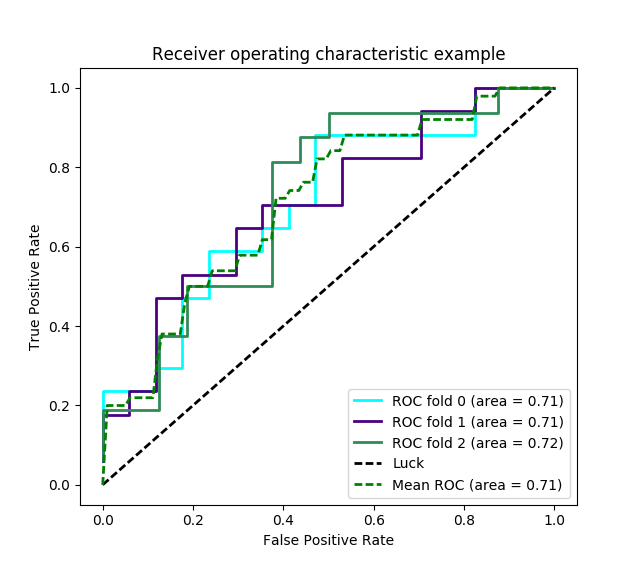 这里简单地不同颜色的线为KFold各次学习的曲线。一般可以比较多种算法,不同算法用不同颜色。
fpr和tpr是根据什么取值的呢?得研究
这里简单地不同颜色的线为KFold各次学习的曲线。一般可以比较多种算法,不同算法用不同颜色。
fpr和tpr是根据什么取值的呢?得研究sklearn.metrics.roc_curve这个函数。分类器fit以后,可以用predict_proba求数据的预测概率,把预测出的概率和真实结果提供给roc_curve就能得若干阈值,以及各阈值下fpr和tpr的值。其中阈值都是从输入的概率中挑出来的。有了roc后auc就好算了。
图中对角的虚直线为随机判断,所以对于不同阈值fpr和tpr总是相等的。auc的意义在于:给一个随机真样本和随机假样本,分类器各预测一个为真值概率a和b,auc等价于a大于b的概率。如果auc大于0.5,那么这个分类器就更容易把真样本预测为真,越不容易把假样本预测为真。
类似的指标还有sklearn.metrics.precision_recall_curve,针对这个曲线也可以计算它的auc。
sklearn.metrics.classification_report可以生成precision、recall等数据的文字报告。